The simultaneous use of more than one CPU or processor core to execute a program or multiple computational threads is called parallel processing or Parallelism. Ideally, parallel processing makes programs run faster because there are more engines (CPUs or Cores) running it. as you all know Datastage supports 2 types of parallelism.
1.Pipeline parallelism.
2.Partition parallelism.
Pipeline Parallelism :
As and when a row/set of rows is/are processed at a particular stage that record or rows is sent out to process at another stage for processing or storing. Below image explains the same in detail.
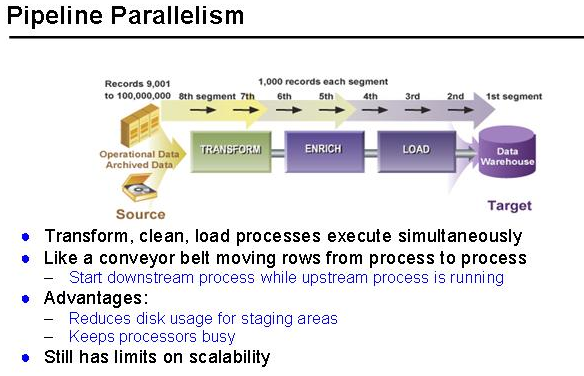
We have set of rows in source and 1k rows being read in a single segment,When ever those rows got processed at Transform,those are being sent to ENRICH and From there to LOAD ,so By this way we can keep processor busy and reduce disk usage for staging.
Partition Parallelism :
Partition Parallel depends on dividing large data into smaller subsets (partitions) across resources ,Goal is to evenly distribute data,some transforms require all data within same group to be in same partition Requires the same transform on all partitions.
Using partition parallelism the same job would effectively be run simultaneously by several processors, each handling a separate subset of the total data, but Each partition is independent of others, there is no concept of “global” state.

Using partition parallelism the same job would effectively be run simultaneously by several processors, each handling a separate subset of the total data, but Each partition is independent of others, there is no concept of “global” state.
Datastage combines both Partition and Pipeline parallelism together to implement ETL Solutions.

0 comments:
Post a Comment